深入HBase存儲模型 大數據中最具挑戰的源碼解析
HBase作為大數據生態系統中的核心組件,其存儲模型的設計與實現是眾多開發者和架構師深感棘手的難點之一。本文將聚焦HBase的存儲架構、數據處理邏輯及服務機制,解析其源碼中的關鍵挑戰點。
一、存儲模型概述
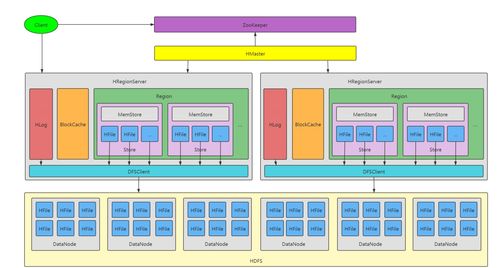
HBase基于Google Bigtable的設計思想,采用LSM-Tree(Log-Structured Merge-Tree)作為底層存儲結構。其存儲模型主要包含以下核心組件:
- Region:數據分片的基本單元,每個Region負責存儲一段連續的行鍵范圍。
- Store:對應于一個列族(Column Family)的存儲單元,每個Store包含一個MemStore和多個HFile。
- HFile:實際存儲數據的文件格式,基于HDFS實現持久化。
二、數據處理流程
HBase的數據寫入流程遵循LSM-Tree的原則:
- 寫入操作首先被記錄到WAL(Write-Ahead Log)以確保數據持久性。
- 數據隨后被寫入MemStore(內存緩沖區),當MemStore達到閾值時,會觸發Flush操作,將數據持久化為HFile。
- 后臺的Compaction進程會定期合并小的HFile,以減少讀取時的I/O開銷,并清理過期數據。
數據讀取則涉及多層查詢:
- 首先檢查BlockCache(讀緩存)。
- 若未命中,則依次搜索MemStore和HFile,通過布隆過濾器(Bloom Filter)快速判斷數據是否存在。
三、源碼難點解析
HBase存儲模型的源碼實現中,最具挑戰的部分包括:
- Region分裂與合并:如何動態調整數據分布,同時保證服務的高可用性。
- Compaction策略:權衡I/O消耗與查詢性能,避免『寫放大』問題。
- 內存管理:MemStore與BlockCache的協同,防止JVM堆內存溢出。
- 分布式事務:基于MVCC(多版本并發控制)的處理機制,保障數據一致性。
四、存儲服務優化
為應對海量數據的存儲與訪問需求,HBase在服務層做了多項優化:
- 利用HDFS的冗余機制保障數據可靠性。
- 通過RegionServer的負載均衡,避免單點瓶頸。
- 支持協處理器(Coprocessor),允許用戶自定義數據處理邏輯。
HBase的存儲模型通過LSM-Tree的巧妙設計和分布式架構的支撐,實現了高吞吐量的數據寫入與靈活的數據查詢。其源碼中復雜的線程調度、資源管理和異常處理機制,正是開發者需要深入理解和攻克的難點。對于希望精通大數據存儲技術的從業者來說,透徹掌握HBase的存儲模型源碼,無疑是提升技術深度的關鍵一步。
如若轉載,請注明出處:http://www.simaoarabica.com.cn/product/26.html
更新時間:2026-02-24 03:06:30