Kafka文件存儲機制、分區策略與數據可靠性保證
Apache Kafka是一個高吞吐量、分布式的消息系統,廣泛應用在實時數據處理和存儲服務中。其核心設計包括文件存儲機制、分區策略與數據可靠性保證,這些機制共同支撐了Kafka的高性能和容錯能力。
一、Kafka文件存儲機制
Kafka的文件存儲機制基于日志結構的設計,將所有消息持久化到磁盤上的日志文件中。關鍵點包括:
- 分段存儲:每個主題分區被劃分為多個日志段(segment),每個段包括.index和.log文件。.log文件存儲實際消息,而.index文件存儲消息的偏移量索引,便于快速檢索。
- 順序寫入:Kafka采用追加寫入(append-only)的方式,消息按順序寫入當前活躍的日志段,這大大提高了磁盤I/O效率,避免了隨機寫入的性能瓶頸。
- 數據保留與清理:Kafka支持基于時間或大小的數據保留策略,例如設置消息在磁盤上保留7天或1GB大小。當數據超出限制時,可以自動刪除舊日志段或壓縮日志以減少存儲空間。
這種存儲機制確保了高吞吐量,因為順序寫入和索引優化減少了磁盤尋址時間,同時分段設計便于管理和擴展。
二、分區策略
分區是Kafka實現并行處理和負載均衡的核心。分區策略決定了消息如何分配到不同分區:
- 輪詢分區:默認策略,消息均勻分布到所有分區,確保負載均衡。適用于無特定順序要求的場景。
- 鍵分區:如果消息指定了鍵(key),Kafka使用哈希函數將相同鍵的消息分配到同一分區,保證同一鍵的消息順序性。這對于需要局部有序的數據(如用戶行為日志)至關重要。
- 自定義分區:用戶可以實現Partitioner接口,根據業務邏輯自定義分區規則,例如基于地理位置或用戶ID分區。
分區的優勢在于:提高并行處理能力,允許消費者組中的多個消費者同時消費不同分區,從而提升整體吞吐量。分區還支持水平擴展,當數據量增加時,可以通過增加分區來分散負載。
三、數據可靠性保證
Kafka通過多副本機制和確認機制確保數據的高可靠性:
- 副本機制:每個分區可以有多個副本(replicas),包括一個領導者(leader)和多個追隨者(follower)。領導者處理所有讀寫請求,追隨者從領導者復制數據。如果領導者故障,Kafka會自動從追隨者中選舉新的領導者,實現故障轉移。
- ISR集合:Kafka維護一個“同步副本”集合(In-Sync Replicas, ISR),包含與領導者數據同步的副本。只有在ISR中的副本才參與領導者選舉,這防止了數據丟失。
- 生產者確認:生產者可以設置acks參數來控制可靠性級別:
- acks=0:不等待確認,可能丟失數據。
- acks=1:等待領導者確認,數據可能丟失(如果領導者故障)。
- acks=all:等待所有ISR副本確認,確保數據持久化,提供最高可靠性。
- 數據持久化:消息一旦被確認,就會持久化到磁盤。結合副本機制,即使部分節點故障,數據也不會丟失。
這些機制使Kafka在分布式環境中能夠處理高并發數據流,同時保證數據的完整性和可用性,適用于金融、日志聚合等對可靠性要求高的場景。
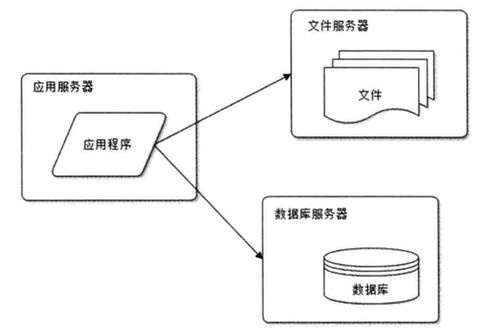
四、在數據處理和存儲服務中的應用
在數據處理和存儲服務中,Kafka的存儲機制、分區策略和可靠性保證共同支持實時數據管道:
- 數據集成:Kafka可以作為數據源,將來自多個應用的數據聚合到中央存儲(如數據湖或數據庫),分區策略確保數據均勻分布。
- 流處理:與流處理框架(如Apache Flink或Spark Streaming)集成,Kafka的分區允許并行處理,提高實時分析效率。
- 容錯存儲:通過副本和確認機制,Kafka在分布式系統中提供可靠的中間存儲層,防止數據丟失,支持系統的高可用性。
Kafka的文件存儲機制、分區策略和數據可靠性保證使其成為現代數據處理架構的基石,能夠高效、可靠地處理大規模實時數據流。
如若轉載,請注明出處:http://www.simaoarabica.com.cn/product/25.html
更新時間:2026-02-24 14:21:36