從單機到分布式數據庫存儲系統的演進 數據處理與存儲服務的變革之路
隨著信息技術的飛速發展,數據處理和存儲系統經歷了從單機到分布式的根本性變革。這一演進不僅反映了計算需求的快速增長,也體現了對高可用性、可擴展性和容錯性的追求。
一、單機數據庫時代
在早期,數據處理主要依賴單機數據庫系統。這類系統將所有數據集中存儲在一臺服務器上,采用關系型數據庫模型(如MySQL、Oracle),事務處理遵循ACID原則。單機數據庫的優點是架構簡單、易于管理,且能保證強一致性。隨著數據量的增長和并發訪問需求的提升,單機系統很快面臨性能瓶頸、單點故障和擴展性限制等問題。
二、分布式數據庫的興起
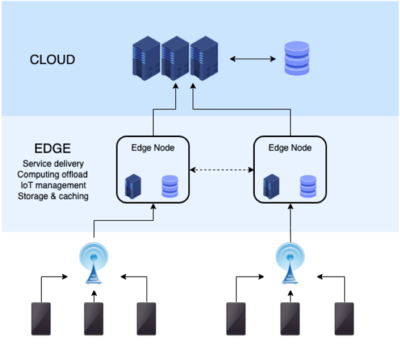
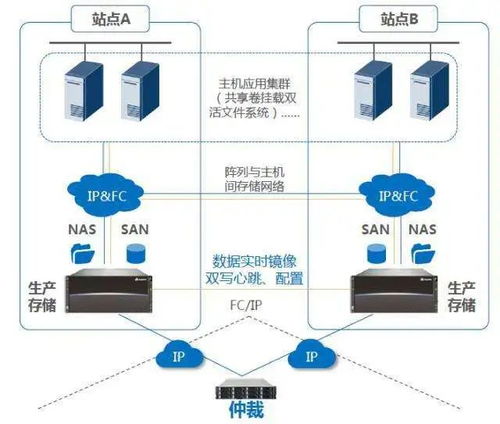
為應對單機系統的局限性,分布式數據庫應運而生。其核心思想是將數據分散到多臺服務器上,通過網絡協同工作。分布式系統通過數據分片、副本機制和負載均衡技術,實現了水平擴展和高可用性。典型的例子包括Google的Bigtable、Amazon的DynamoDB,以及開源的Cassandra和MongoDB。這些系統在設計時注重分區容錯性,并在此基礎上權衡一致性和可用性(如CAP理論)。
三、數據處理服務的演進
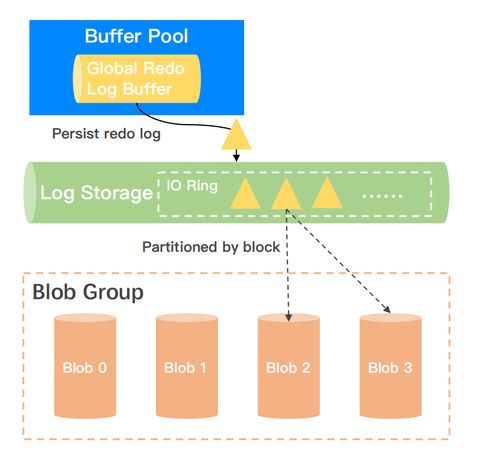
與存儲系統并行,數據處理服務也從集中式向分布式發展。早期,數據處理依賴于單機上的ETL工具和批處理作業。隨著大數據時代的到來,分布式計算框架如Hadoop和Spark成為主流,它們能夠對海量數據進行并行處理。流處理技術(如Apache Kafka和Flink)使得實時數據分析成為可能,進一步推動了數據處理服務的演進。
四、云原生與未來趨勢
云原生技術推動了數據庫和存儲服務的進一步革新。云數據庫服務(如AWS Aurora、Google Spanner)提供了彈性伸縮、全球分布和多租戶支持。存儲與計算分離的架構(如Snowflake)實現了資源的高效利用。隨著人工智能和邊緣計算的發展,分布式系統將更加智能化和去中心化,支持更復雜的異構數據處理需求。
結語
從單機到分布式,數據庫存儲系統的演進不僅是技術的飛躍,更是應對數據爆炸和業務多樣化的必然選擇。這一歷程彰顯了技術創新在提升數據處理能力、保障服務可靠性方面的核心作用,為數字化時代的持續發展奠定了堅實基礎。
如若轉載,請注明出處:http://www.simaoarabica.com.cn/product/24.html
更新時間:2026-02-24 15:49:03