Google如何引爆大數據時代 解密GFS、MapReduce與BigTable三大奠基論文
隨著互聯網的飛速發展,海量數據的產生與處理需求推動了一場技術革命。在這一浪潮中,Google發布的三篇關鍵技術論文——《The Google File System》(GFS)、《MapReduce:Simplified Data Processing on Large Clusters》和《Bigtable: A Distributed Storage System for Structured Data》——奠定了大數據時代的基石。這些論文不僅解決了Google自身的數據存儲與處理挑戰,更開源了思想,催生了Hadoop等開源生態系統,徹底改變了數據處理和存儲服務的格局。
1. Google文件系統(GFS):分布式存儲的里程碑
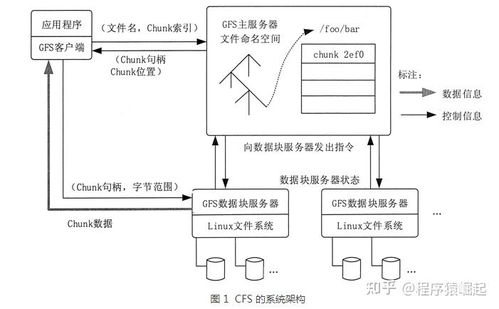
GFS論文于2003年發布,它提出了一種可擴展的分布式文件系統,專為處理海量數據而設計。GFS的核心思想是將數據分割成固定大小的塊(chunks),并分布到多個廉價的商用服務器上,通過主節點(Master)管理元數據,而數據節點(ChunkServers)負責實際存儲。這種架構不僅提高了容錯性(通過冗余副本實現),還支持高吞吐量的數據訪問,尤其適合大規模批處理任務。GFS的發布啟發了后來的Hadoop Distributed File System(HDFS),成為大數據存儲的典范。
2. MapReduce:簡化大規模數據處理的編程模型
緊隨GFS,Google在2004年發布了MapReduce論文,它提供了一種簡單的編程模型,用于并行處理海量數據集。MapReduce將計算任務分解為兩個階段:Map(映射)和Reduce(歸約)。在Map階段,數據被分割并分配到多個節點上進行處理;在Reduce階段,中間結果被聚合生成最終輸出。這種模型屏蔽了分布式系統的復雜性,使開發者能專注于業務邏輯,而無需擔心節點故障、數據分區等底層細節。MapReduce的靈感催生了Apache Hadoop的MapReduce實現,廣泛應用于日志分析、網頁索引和機器學習等領域。
3. BigTable:面向結構化數據的分布式存儲服務
2006年,Google發表了BigTable論文,描述了一個高性能的、分布式的結構化數據存儲系統。BigTable建立在GFS之上,使用稀疏、分布式、多維排序映射表來存儲數據,支持動態擴展和低延遲訪問。它通過行鍵、列族和時間戳來組織數據,適用于各種應用,如網頁索引、用戶數據管理和實時查詢。BigTable的設計影響了多個開源項目,如Apache HBase和Cassandra,為NoSQL數據庫的興起鋪平了道路。
數據處理和存儲服務的深遠影響
這三篇論文共同構建了一個完整的數據處理與存儲生態系統:GFS提供底層存儲,MapReduce處理數據,BigTable管理結構化信息。它們不僅解決了Google內部的海量數據挑戰,還通過開源社區(如Hadoop生態系統)推廣到全球,賦能企業處理PB級數據。從電子商務到社交媒體,從科學研究到人工智能,大數據技術已成為現代科技的核心驅動力。
Google的這三篇論文不僅是技術突破,更是思維方式的革新。它們證明了通過分布式、容錯和可擴展的設計,能夠高效應對數據爆炸的挑戰。隨著云計算和邊緣計算的發展,這些理念仍在不斷演化,持續推動著大數據時代的進步。
如若轉載,請注明出處:http://www.simaoarabica.com.cn/product/17.html
更新時間:2026-02-24 23:39:42